Ứng dụng của thuật toán rừng ngẫu nhiên – Random Forests, đây là một dạng nâng cao của Cây quyết định – decision tree; Rừng ngẫu nhiên là một thuật toán học máy linh hoạt, dễ sử dụng , tạo ra kết quả tuyệt vời ngay cả khi không điều chỉnh siêu tham số. Nó cũng là một trong những thuật toán được sử dụng nhiều nhất, do tính đơn giản và đa dạng của nó (nó có thể được sử dụng cho cả nhiệm vụ phân loại và hồi quy).
Nổi dung nổi bậc
Thuật toán rừng ngẫu nhiên – Random Forests
Thuật toán Random Forest là gì ?
Random Forest là một thuật toán học máy phổ biến thuộc về kỹ thuật học có giám sát. Nó có thể được sử dụng cho cả vấn đề Phân loại và Hồi quy trong ML. Nó dựa trên khái niệm học tập theo nhóm, là một quá trình kết hợp nhiều bộ phân loại để giải quyết một vấn đề phức tạp và để cải thiện hiệu suất của mô hình.
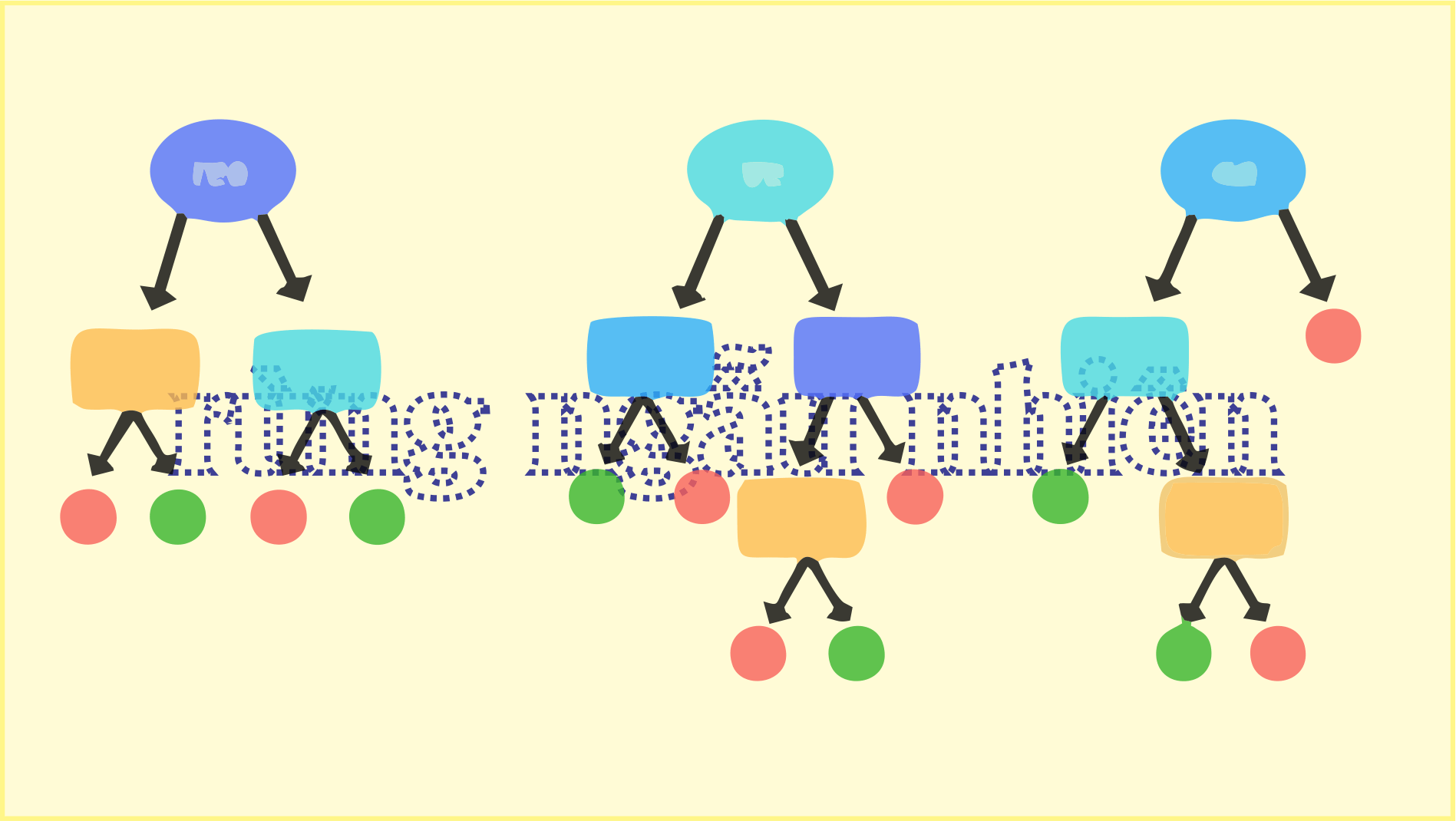
Như tên cho thấy, “Rừng ngẫu nhiên là một bộ phân loại chứa một số cây quyết định trên các tập con khác nhau của tập dữ liệu đã cho và lấy giá trị trung bình để cải thiện độ chính xác dự đoán của tập dữ liệu đó.” Thay vì dựa vào một cây quyết định, rừng ngẫu nhiên lấy dự đoán từ mỗi cây và dựa trên đa số phiếu dự đoán, và nó dự đoán kết quả cuối cùng.
Số lượng cây lớn hơn trong rừng dẫn đến độ chính xác cao hơn và ngăn ngừa vấn đề trang bị quá mức.
Sơ đồ dưới đây giải thích hoạt động của thuật toán Rừng ngẫu nhiên:
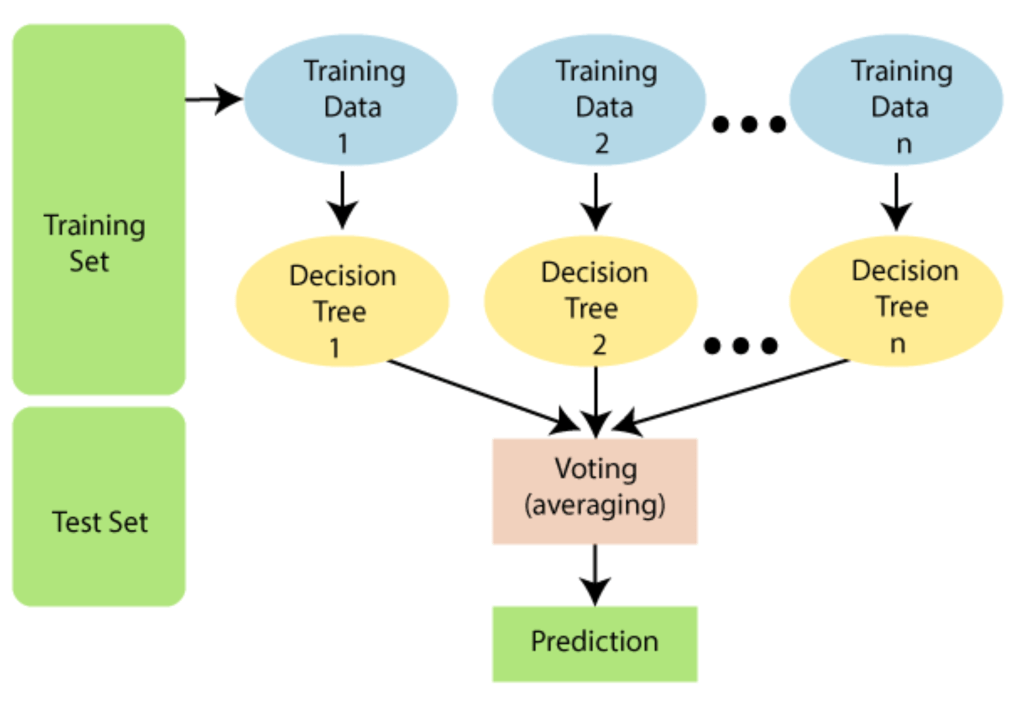
Cách hoạt động của rừng ngẫu nhiên
Rừng ngẫu nhiên là một thuật toán học có giám sát . “Khu rừng” mà nó xây dựng là một tập hợp các cây quyết định, thường được đào tạo theo phương pháp “đóng bao”. Ý tưởng chung của phương pháp đóng gói là sự kết hợp của các mô hình học tập sẽ làm tăng kết quả chung.
Nói một cách đơn giản: rừng ngẫu nhiên xây dựng nhiều cây quyết định và kết hợp chúng lại với nhau để có được dự đoán chính xác và ổn định hơn.
Một lợi thế lớn của rừng ngẫu nhiên là nó có thể được sử dụng cho cả các bài toán phân loại và hồi quy, vốn tạo nên phần lớn các hệ thống học máy hiện nay.
Các giả định cho Rừng Ngẫu nhiên
Vì rừng ngẫu nhiên kết hợp nhiều cây để dự đoán lớp của tập dữ liệu, nên có thể một số cây quyết định có thể dự đoán đầu ra chính xác, trong khi những cây khác thì không. Nhưng cùng nhau, tất cả các cây đều dự đoán sản lượng chính xác. Do đó, dưới đây là hai giả định để có bộ phân loại rừng Ngẫu nhiên tốt hơn:
- Phải có một số giá trị thực tế trong biến đặc điểm của tập dữ liệu để bộ phân loại có thể dự đoán kết quả chính xác hơn là kết quả đoán.
- Các dự đoán từ mỗi cây phải có mối tương quan rất thấp.
Tại sao sử dụng Rừng ngẫu nhiên?
Dưới đây là một số điểm giải thích tại sao chúng ta nên sử dụng thuật toán Rừng ngẫu nhiên:
- Mất ít thời gian đào tạo hơn so với các thuật toán khác.
- Nó dự đoán đầu ra với độ chính xác cao, ngay cả đối với tập dữ liệu lớn, nó chạy hiệu quả.
- Nó cũng có thể duy trì độ chính xác khi một phần lớn dữ liệu bị thiếu.
Thuật toán Random Forest hoạt động như thế nào?
Random Forest hoạt động trong hai giai đoạn đầu tiên là tạo ra khu rừng ngẫu nhiên bằng cách kết hợp N cây quyết định, và thứ hai là đưa ra dự đoán cho mỗi cây được tạo ra trong giai đoạn đầu tiên.
Quá trình làm việc có thể được giải thích trong các bước và sơ đồ dưới đây:
Bước 1: Chọn điểm dữ liệu K ngẫu nhiên từ tập huấn luyện.
Bước 2: Xây dựng cây quyết định liên kết với các điểm dữ liệu đã chọn (Tập con).
Bước 3: Chọn số N cho cây quyết định mà bạn muốn xây dựng.
Bước 4: Lặp lại Bước 1 & 2.
Bước 5: Đối với các điểm dữ liệu mới, hãy tìm các dự đoán của từng cây quyết định và gán các điểm dữ liệu mới cho danh mục giành được đa số phiếu bầu.
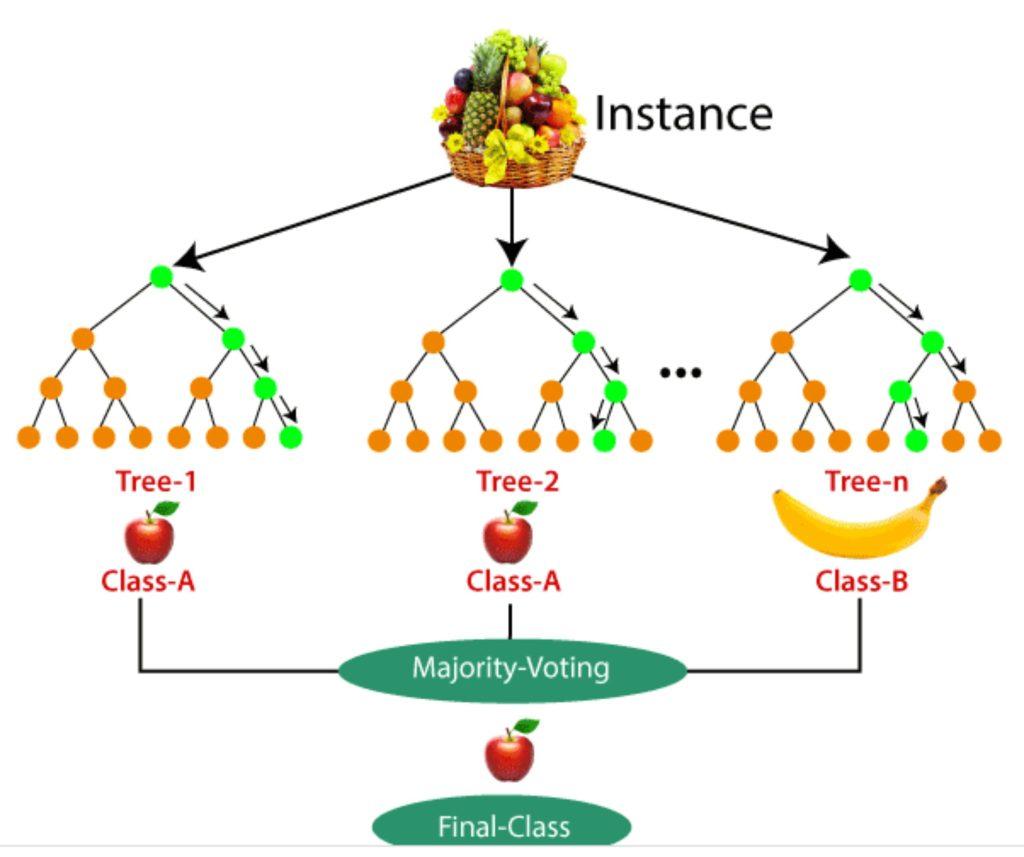
Ví dụ: Giả sử có một tập dữ liệu chứa nhiều hình ảnh trái cây. Vì vậy, tập dữ liệu này được cung cấp cho bộ phân loại rừng ngẫu nhiên. Tập dữ liệu được chia thành các tập con và được cấp cho mỗi cây quyết định. Trong giai đoạn huấn luyện, mỗi cây quyết định tạo ra một kết quả dự đoán và khi một điểm dữ liệu mới xảy ra, thì dựa trên phần lớn kết quả, bộ phân loại Rừng Ngẫu nhiên dự đoán quyết định cuối cùng. Hãy xem xét hình ảnh dưới đây:
Tầm quan trọng của tính năng rừng ngẫu nhiên
Một chất lượng tuyệt vời khác của thuật toán rừng ngẫu nhiên là rất dễ dàng đo lường tầm quan trọng tương đối của từng tính năng đối với dự đoán. Sklearn cung cấp một công cụ tuyệt vời để đo lường tầm quan trọng của một tính năng bằng cách xem xét mức độ mà các nút cây sử dụng tính năng đó làm giảm tạp chất trên tất cả các cây trong rừng. Nó tự động tính điểm số này cho mỗi tính năng sau khi đào tạo và chia tỷ lệ kết quả để tổng của tất cả mức độ quan trọng bằng một.
Nếu bạn không biết cây quyết định hoạt động như thế nào hoặc lá hay nút là gì, thì đây là một mô tả hay từ Wikipedia: “Trong cây quyết định, mỗi nút bên trong đại diện cho một ‘thử nghiệm’ trên một thuộc tính (ví dụ: đồng xu lật xuất hiện đầu hoặc đuôi), mỗi nhánh đại diện cho kết quả của bài kiểm tra và mỗi nút lá đại diện cho một nhãn lớp (quyết định được thực hiện sau khi tính toán tất cả các thuộc tính). Một nút không có con là một lá ”.
Bằng cách xem xét tầm quan trọng của tính năng, bạn có thể quyết định tính năng nào có thể bị loại bỏ vì chúng không đóng góp đủ (hoặc đôi khi không đóng góp gì) cho quá trình dự đoán. Điều này rất quan trọng vì một quy tắc chung trong học máy là bạn càng có nhiều tính năng thì mô hình của bạn càng có nhiều khả năng bị trang bị quá mức và ngược lại.
Sự khác biệt giữa cây quyết định và rừng ngẫu nhiên
Mặc dù một khu rừng ngẫu nhiên là một tập hợp các cây quyết định, có một số khác biệt.
Nếu bạn nhập một tập dữ liệu đào tạo với các tính năng và nhãn vào cây quyết định, nó sẽ hình thành một số bộ quy tắc, sẽ được sử dụng để đưa ra các dự đoán.
Ví dụ: để dự đoán liệu một người có nhấp vào quảng cáo trực tuyến hay không, bạn có thể thu thập các quảng cáo mà người đó đã nhấp vào trong quá khứ và một số tính năng mô tả quyết định của họ. Nếu bạn đặt các tính năng và nhãn vào cây quyết định, nó sẽ tạo ra một số quy tắc giúp dự đoán liệu quảng cáo có được nhấp vào hay không. Để so sánh, thuật toán rừng ngẫu nhiên chọn ngẫu nhiên các quan sát và đặc điểm để xây dựng một số cây quyết định và sau đó tính trung bình các kết quả.
Một sự khác biệt khác là cây quyết định “sâu” có thể bị quá mức. Hầu hết thời gian, rừng ngẫu nhiên ngăn chặn điều này bằng cách tạo các tập hợp con ngẫu nhiên của các đối tượng địa lý và xây dựng các cây nhỏ hơn bằng cách sử dụng các tập hợp con đó. Sau đó, nó kết hợp các cây con. Điều quan trọng cần lưu ý là điều này không phải lúc nào cũng hoạt động và nó cũng làm cho quá trình tính toán chậm hơn, tùy thuộc vào số lượng cây mà khu rừng ngẫu nhiên xây dựng.
Các ứng dụng của Rừng ngẫu nhiên
Chủ yếu có bốn lĩnh vực mà Rừng ngẫu nhiên chủ yếu được sử dụng:
- Ngân hàng: Lĩnh vực ngân hàng chủ yếu sử dụng thuật toán này để xác định rủi ro cho vay.
- Y học: Với sự trợ giúp của thuật toán này, các xu hướng bệnh tật và nguy cơ của bệnh có thể được xác định.
- Sử dụng đất: Chúng tôi có thể xác định các khu vực sử dụng đất tương tự bằng thuật toán này.
- Tiếp thị: Các xu hướng tiếp thị có thể được xác định bằng cách sử dụng thuật toán này.
Ưu điểm của Rừng ngẫu nhiên
- Random Forest có khả năng thực hiện cả hai nhiệm vụ Phân loại và Hồi quy.
- Nó có khả năng xử lý các tập dữ liệu lớn với kích thước cao.
- Nó nâng cao độ chính xác của mô hình và ngăn chặn vấn đề trang bị quá mức.
Nhược điểm của Rừng ngẫu nhiên
- Mặc dù rừng ngẫu nhiên có thể được sử dụng cho cả nhiệm vụ phân loại và hồi quy, nó không phù hợp hơn cho các nhiệm vụ Hồi quy.
Các siêu tham số quan trọng
Các siêu tham số trong rừng ngẫu nhiên được sử dụng để tăng khả năng dự đoán của mô hình hoặc để làm cho mô hình nhanh hơn. Hãy xem các siêu tham số của chức năng rừng ngẫu nhiên tích hợp sẵn của sklearns.
TĂNG SỨC MẠNH DỰ ĐOÁN
Thứ nhất, có siêu tham số n_estimators , chỉ là số cây mà thuật toán xây dựng trước khi lấy phiếu bầu tối đa hoặc lấy giá trị trung bình của các dự đoán. Nói chung, số lượng cây cao hơn làm tăng hiệu suất và làm cho các dự đoán ổn định hơn, nhưng nó cũng làm chậm quá trình tính toán.
Một siêu tham số quan trọng khác là max_features, là số lượng tối đa các đối tượng mà rừng ngẫu nhiên xem xét để tách một nút. Sklearn cung cấp một số tùy chọn, tất cả đều được mô tả trong.
Siêu tham số quan trọng cuối cùng là min_sample_leaf. Điều này xác định số lượng lá tối thiểu cần thiết để tách một nút bên trong.
TĂNG TỐC ĐỘ CỦA MÔ HÌNH
Siêu tham số n_jobs cho động cơ biết nó được phép sử dụng bao nhiêu bộ xử lý. Nếu nó có giá trị là một, nó chỉ có thể sử dụng một bộ xử lý. Giá trị “-1” có nghĩa là không có giới hạn.
Siêu tham số random_state làm cho đầu ra của mô hình có thể sao chép được. Mô hình sẽ luôn tạo ra cùng một kết quả khi nó có một giá trị xác định là random_state và nếu nó được cung cấp cùng một siêu tham số và cùng một dữ liệu huấn luyện.
Cuối cùng, có oob_score (còn được gọi là lấy mẫu oob), là một phương pháp xác thực chéo rừng ngẫu nhiên. Trong lần lấy mẫu này, khoảng một phần ba dữ liệu không được sử dụng để đào tạo mô hình và có thể được sử dụng để đánh giá hoạt động của nó. Những mẫu này được gọi là mẫu xuất túi. Nó rất giống với phương pháp xác thực bỏ một-ra-chéo, nhưng hầu như không có gánh nặng tính toán bổ sung nào đi cùng với nó.


